A Generative Adversarial Network, or GAN, is a type of neural network architecture for generative modeling invented by Ian Goodfellow. This model is considered as a major advancement in deep learning since they can imagine new things. To be more clear, if you give them a training set of something like images , they can make entirely new images that are realistic even though these images have never been seen before. Let’s check out some of the things you can do with GANs. This blog post is written for people interested in GAN application , it is not necessary to have a mathematical background to fully understand the listed applications.
Next Video Frame Prediction

One example of a task that requires the use of GANs is predicting the next frame in a video. Because there are many different things that can happen in the next time step, there are many frames that can appear in a sequence after the current image. In this case traditional approaches for predicting the next video frame often become very blurry because there are many things that can happen. When they try to represent the distribution over the next frame using a single image, many different possible images are averaged together and result in a blurry mess. A work done by William Lotter and his collaborators published in 2016 has shown how GANs are effective in predicting next video frames.
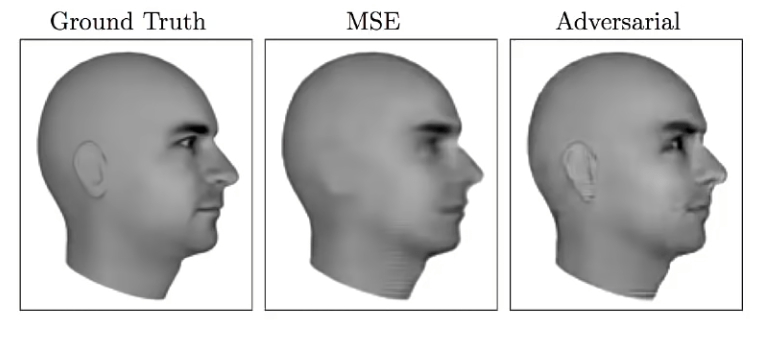
Single Image Super-Resolution

Another task that requires being able to generate good data is super resolution of images. Ledig et al have used GANs for constructing super resolution images from low resolution ones. In this example, the original image on the right is downsampled to about half of its original resolution. In the figure above, several ways are shown for reconstructing the high resolution version of the image. By using the bicubic interpolation method we get a relatively blurry image. The remaining two images show different ways of using machine learning to actually learn to create a high resolution images that look like the data distribution. So here the model tries to use its knowledge of what high resolution images look like to provide details that have been lost in the downsampling process. The new high resolution image generated by SRGAN may not be perfectly accurate and may not perfectly agree with reality but it at least look like something plausible and visually pleasing.
iGAN
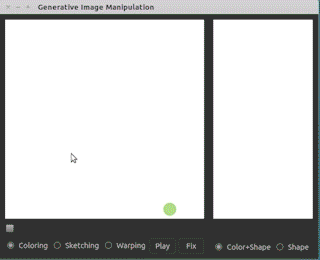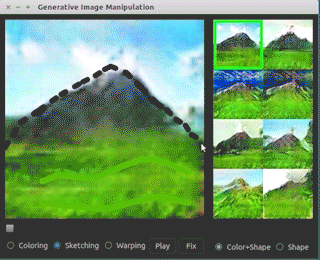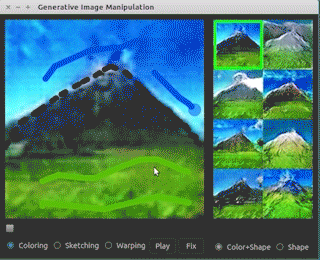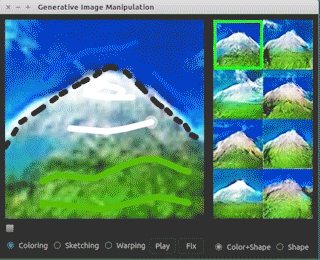
There are many different applications that involve interaction between human beings and image generation process. One of these is a collaboration between University of Berkeley and Adobe called iGAN where « i » stands for « interactive ». The basic idea of iGAN is that it assists a human to create artwork. The human artists draws few green lines and then a generative model is used to search over the space of possible images that resemble what the human has begun to draw even though the human doesn’t have much artistic ability. Humans can draw just a simple black triangle and it will be turned into a photo quality mountain! This is such a popular area that there have been many papers working on this subject which came out through recent years. Brock et al. have worked on Introspective adversarial networks which also provide this ability to provide interactive photo editing. A human can begin editing a photo and a generative model will automatically update the photo to keep it appearing realistic.
NVIDIA GauGAN

Park et al have worked on GauGAN, named after post-Impressionist painter Paul Gauguin, which creates photorealistic images from segmentation maps, which are labeled sketches that depict the layout of a scene. Artists can use paintbrush and paint bucket tools to design their own landscapes with labels like river, rock and cloud. A style transfer algorithm allows creators to apply filters — changing a daytime scene to sunset, or a photorealistic image to a painting. Users can even upload their own filters to layer onto their masterpieces, or upload custom segmentation maps and landscape images as a foundation for their artwork
Image to Image Translation

A recent paper called Image to Image translation shows how conditional Generative Adversarial Networks can be trained to implement many of these multi-modal output distributions where an input can be mapped to many different possible outputs. One example is taking sketches and turning them into photos, in this case it is very easy to train the model because photos can be converted to sketches by using an edge extractor and that provides very large training sets for the mapping from sketch to image, essentially in this case the generative model learns to invert the edge detection process even though the inverse has many possible inputs that correspond to the same output and vice versa. The same model can also convert area photographs to maps and can take descriptions of scenes in terms of which object category should appear in each pixel and turn them into photo-realistic images.
The StackGAN Model
Zhang et al have worked synthesizing photo-realistic images from text descriptions. This model is really good at taking a textual representation of a bird then generating a high resolution photo of this bird matching that description. These photos have never been seen before and are totally imaginery! It’s not just running image search on a database, in fact the GAN is drawing a sample from the probability distribution over all hypothetical images matching that description.
NVIDIA GANimal
We’ve all passed a Chihuahua on the street that’s the size of a guinea pig with the attitude of a German Shepherd. With GANimal, you can bring your pet’s alter ego to life by projecting their expression and pose onto other animals. Once you input an image into the GANimal app, the image translation network unleashes your pet’s true self by projecting their unique characteristics onto everything from a lynx to a Saint Bernard. Liu et al drew inspiration from the human capability of picking up the essence of a novel object from asmall number of examples and generalizing from there.
CycleGAN

At the University Of Berkeley, Zhu et al have worked on a model called CycleGAN is especially good at unsupervised image to image translation. In the video below we can see how CycleGAN is able to transform a video of a horse to a video of a zibra. Because the training is totally unsupervised, we can see that it changes a few things beside a horse. As we know, horses and zibras live in different environments, the model has learned to change the background as well as the image of the horse itself. The background comes out looking more like an african grassland.
These are all several reasons that we might want to study Generative Models and especially Generative Adversarial Networks GANs ranging from the different kinds of mathematical abilities they force us to develop to the many different applications we can carry out once we have these kinds of models. Did I miss an interesting application of GANs or a great paper on specific GAN application?
Please let me know in the comments.
